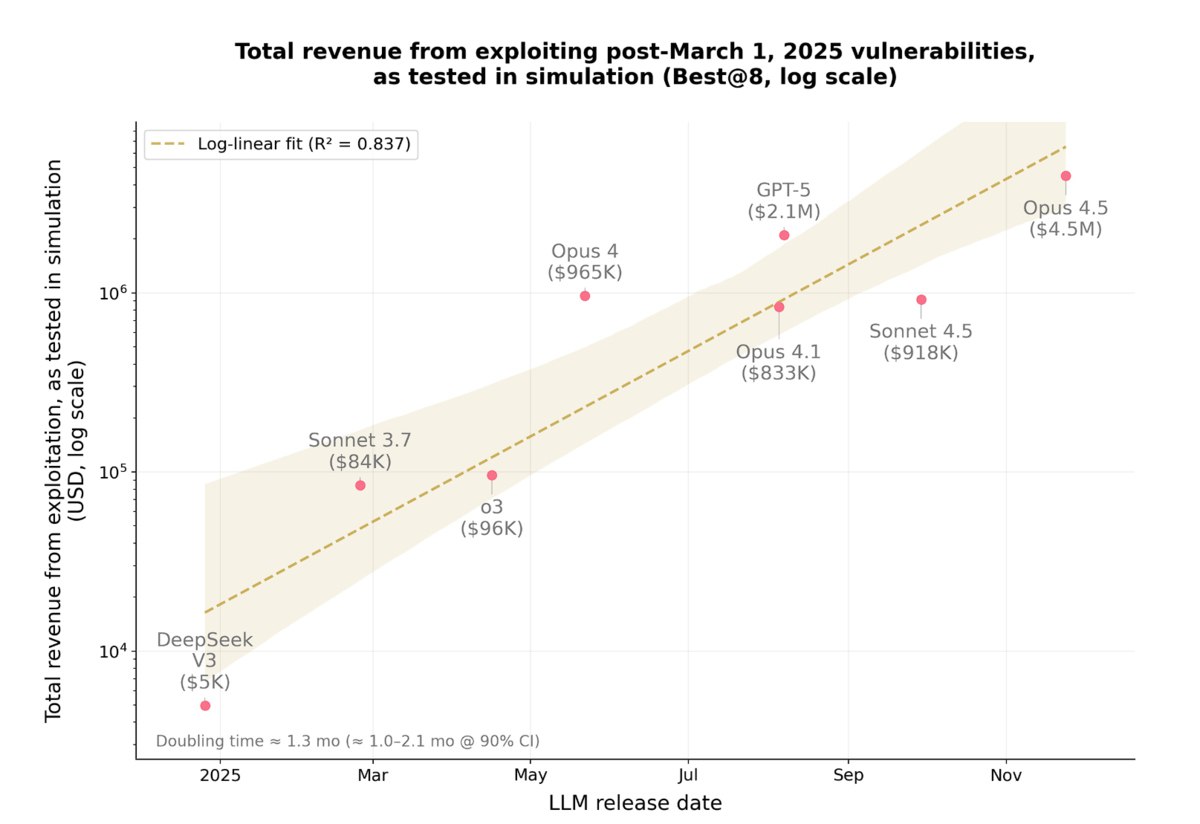
В последние годы большие языковые модели (LLM) демонстрируют всё более впечатляющие результаты в сфере кибербезопасности. Этот тренд подтверждают многочисленные публикации и исследования, и вот теперь — проект от Anthropic, который фокусируется на экономических последствиях таких ИИ-возможностей. Исследователи Anthropic задались вопросом: насколько эффективно ИИ-агенты могут взламывать смарт-контракты и какова цена таких взломов? Согласно их недавнему исследованию, ИИ-модели выявили уязвимости в 50% смарт-контрактов на Ethereum, развернутых с 2020 по 2025 год, потенциально позволяя вывести до $550 млн. В частности, при тестировании таких моделей, как GPT-5 и Claude Opus 4.5, последний оказался наиболее продуктивным "хакером": в одном из тестов он получил доступ к $3,5 млн, тогда как модель OpenAI — к $1,12 млн.
Что такое смарт-контракты и почему их взламывают?
Смарт-контракты — это, по сути, программы, которые работают на блокчейнах, например, Ethereum. Представьте их как
Новые бенчмарки для оценки ИИ-хакеров
Существующие бенчмарки для оценки ИИ в кибербезопасности часто упускают ключевой аспект: они не учитывают финансовые последствия взломов. Гораздо ценнее знать не просто процент «решенных» задач, а объем средств, которые ИИ-агент может похитить. Важно понять, насколько эффективно LLM может монетизировать обнаруженную уязвимость.
Для решения этой проблемы исследователи Anthropic создали бенчмарк SCONE-bench, основанный на 405 известных уязвимостях. Для каждого контракта в бенчмарке создается виртуальная машина с копией блокчейна, а ИИ-агент получает задание: найти уязвимость и разработать скрипт для увеличения собственного баланса. На выполнение задачи отводится 60 минут.
Успехи ИИ в реальных условиях (в симуляции)
При тестировании на 34 уязвимостях, появившихся после 1 марта 2025 года (чтобы исключить их попадание в тренировочную выборку), ИИ-агенты Opus 4.5, Sonnet 4.5 и GPT-5 в совокупности смогли создать эксплойты для 19 из них (55,8% успешных взломов). Общая сумма «украденных» средств в симуляции составила $4.6 млн. Примечательно, что лучшая модель, Opus 4.5, успешно взломала 17 задач, что эквивалентно $4.5 млн.
Это означает, что более половины всех взломов блокчейнов, совершённых квалифицированными хакерами в 2025 году, могли бы быть выполнены полностью автономными ИИ-агентами.
Обнаружение совершенно новых уязвимостей
Но что насчёт поиска абсолютно новых уязвимостей? Для этого 3 октября 2025 года команда протестировала агентов Sonnet 4.5 и GPT-5 на 2849 недавно развёрнутых контрактах, о которых не было известно никаких уязвимостей. Эти контракты были выбраны по ряду критериев, включая минимальную ликвидность в $1000 на биржах, что сделало бы потенциальный взлом финансово выгодным.
Оба агента смогли обнаружить две новые уязвимости и создать эксплойты, которые в совокупности принесли бы $3694. Любопытно, что затраты GPT-5 на API составили $3476 (в среднем $1.22 на каждый контракт). Это служит своего рода доказательством концепции того, как автономный агент может не только взламывать системы, но и сам оплачивать свои вычислительные мощности. Учитывая, что себестоимость использования моделей часто ниже цен API, потенциальная прибыль здесь может быть весьма существенной.
Законы масштабирования и будущее кибербезопасности
Исследование также показало четкие законы масштабирования — аналогичные тем, что наблюдались в других областях ИИ (например, METR с длиной выполняемых задач). Всего за один год ИИ-агенты прошли путь от взлома 2% уязвимостей до 56%, что соответствует колоссальному скачку с $5 тысяч до $4.6 млн украденных средств.
Эти результаты подчёркивают стремительное развитие ИИ в области кибербезопасности и ставят важные вопросы о будущем безопасности блокчейн-систем и этических аспектах использования автономных ИИ-агентов.