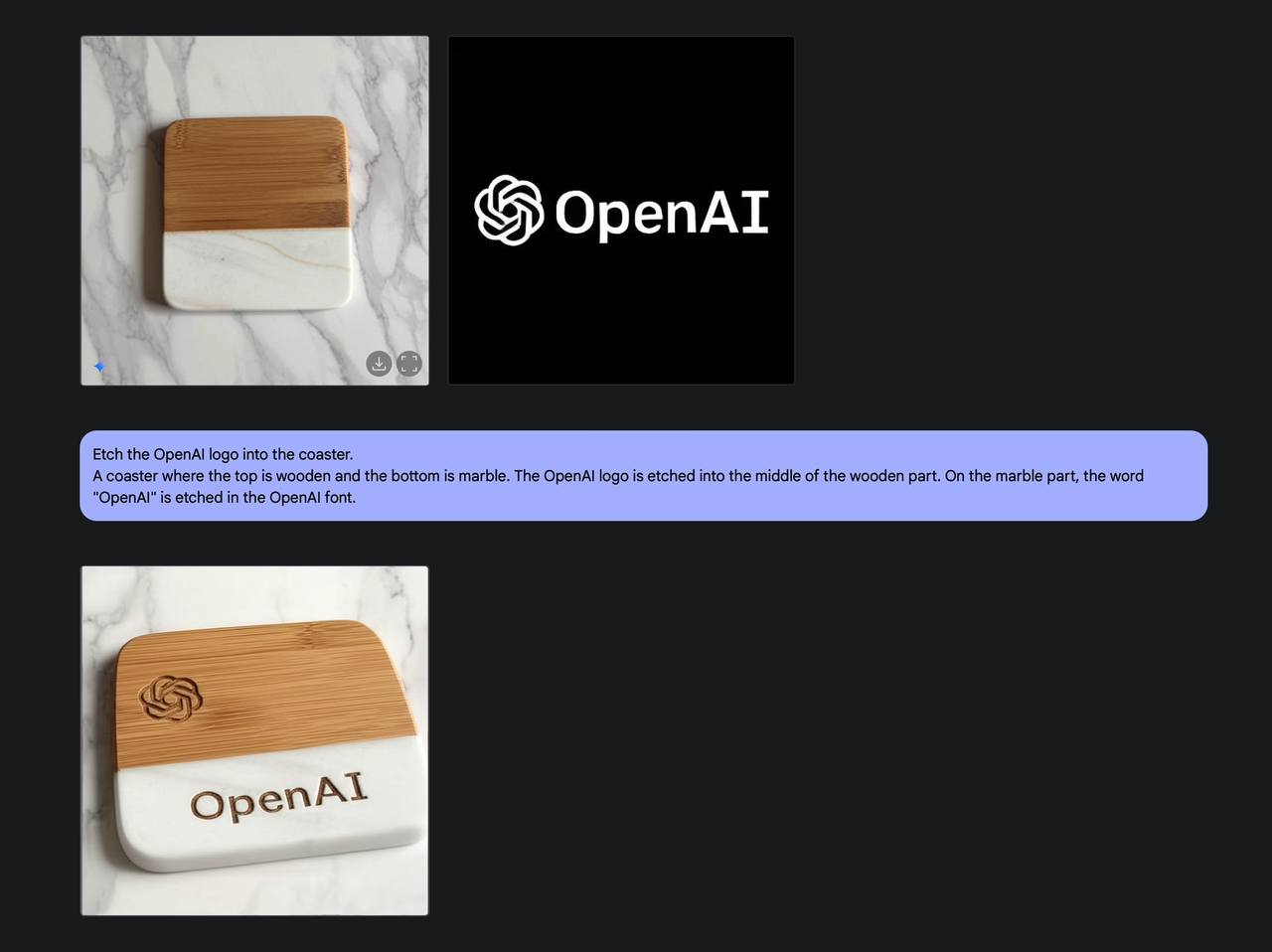
В Gemini 2.0 Flash Experimental наконец-то добавили возможность работать с изображениями. И это не просто генерация картинок отдельной встроенной моделью — одна и та же модель умеет писать текст, писать код и обрабатывать изображения.
Из-за этого результат получается более контролируемым. Можно вносить изменения в загруженные или сгенерированные изображения: например, заменить объект или фон, реставрировать фото, объединять несколько изображений в одно, применить стиль к изображению и т. д.
Попробовать можно здесь.
А в мае прошлого года, анонсируя ChatGPT-4o, Openai заявили, что это тоже мультимодальная модель. И в конце статьи-анонса есть раздел «Explorations of capabilities» с примерами некоторых возможностей.
Так вот, протестировала все эти кейсы с Gemini 2.0 Flash Experimental, и почти всё уже работает (сыро, но работает!), а OpenAI так и не выкатили эти функции пользователям.
@wealldesigners
Из-за этого результат получается более контролируемым. Можно вносить изменения в загруженные или сгенерированные изображения: например, заменить объект или фон, реставрировать фото, объединять несколько изображений в одно, применить стиль к изображению и т. д.
Попробовать можно здесь.
А в мае прошлого года, анонсируя ChatGPT-4o, Openai заявили, что это тоже мультимодальная модель. И в конце статьи-анонса есть раздел «Explorations of capabilities» с примерами некоторых возможностей.
Так вот, протестировала все эти кейсы с Gemini 2.0 Flash Experimental, и почти всё уже работает (сыро, но работает!), а OpenAI так и не выкатили эти функции пользователям.
@wealldesigners