А теперь, для любителей локальных моделей: Gemma 3 QAT
Что-то мы все про протоетарщину да и протоетарщину. А что насчет локальных моделей?
Надо сказать, что этом поприще у маленькмх опенсорных моделей тоже наблюдается какой-то фантастический буст. Например, Gemma 3 27B в кодинге показывает результаты, сопоставимые с GPT-4o-mini.
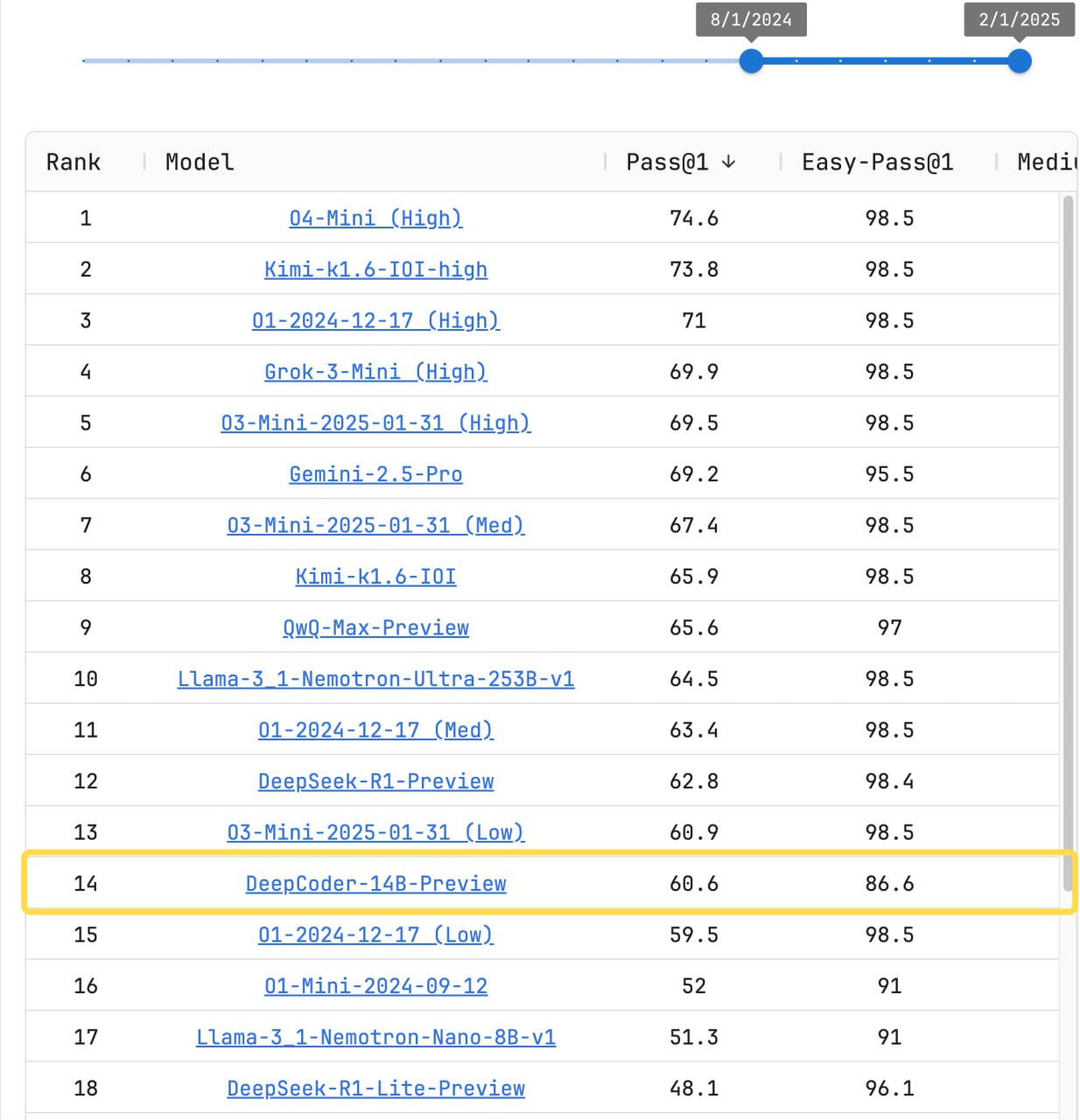
А из ризонинг моделей, как упоминал ранее, QwQ 32B на уровне Claude 3.7 Sonnet Thinking, а DeepCoder 14B (это новая спец. моделька от создателей DeepSeek) на уровне o3-mini (low).
Ну, и опять эксклюзив - на агентские задачи по кодингу, неожиданно вырвалась вперед моделька OpenHands LM 32B от ребят из OpenHands, которые дотренировали ее из Qwen Coder 2.5 Instruct 32B на своем "тренажере для агентов" SWE-Gym, опередив в итоге в SWE-bench даже огромную Deepseek V3 0324. В общем, OpenHands молодцы! Кстати, недавно их Code-агент взял новую соту (SoTA - State of The Art) в SWE-bench Verified. Так, что могу всем смело рекомендовать их блог.
Ух, ну и перенасытил я всех всего лишь одним абзацем!
В общем, что сказать-то хотел - ребята из Google посмотрели, значит, на свою Gemma 3 и увидели, что, при всей своей красоте, она довольно тяжелая все равно оказалась для консьюмерских ПК/GPU, ну и разразились они какой-то крутой квантизацией, которая называется QAT (Quantization-Aware Training). Что это за QAT такой мы тут разбираться не будем - просто для важно знать, что эта хитрая техника квантизации уменьшает требования моделей к железу до 4-х раз, при этом почти не влияя на уровень "интеллекта" модели.
Действительно ли это так? Давайте проверим на примере Gemma 12B IT QAT (4bit). Кстати, специальные MLX-квант-веса, оптимизированные для маководов (я) доступны по ссылке.
Так вот, моделька эта запускается через LMStudio в две кнопки.
В итоге, ответы действительно у нее неплохие, какую-то несложную кодогенерацию она явно вытянет. На, и русский язык ее оказался безупречным (см. скрины). Более того, после моего замечания она, как будто, даже вывезла задачу с генерацией параллельной генерации эмбеддингов (сама решила взять для этого SemaphoreSlim). С использованием Parallel уже не справилась, т. к. начала await юзать внутри Parallel.For (сорри за жаргон, если вы не дотнетчик ). Но в целом, у меня впечатления отличные!
А как у вас себя ведут локальные модельки? С какими задачами справляются, а с какими нет? И какие модели вы используете локально? (если вообще используете)
Что-то мы все про протоетарщину да и протоетарщину. А что насчет локальных моделей?
Надо сказать, что этом поприще у маленькмх опенсорных моделей тоже наблюдается какой-то фантастический буст. Например, Gemma 3 27B в кодинге показывает результаты, сопоставимые с GPT-4o-mini.
А из ризонинг моделей, как упоминал ранее, QwQ 32B на уровне Claude 3.7 Sonnet Thinking, а DeepCoder 14B (это новая спец. моделька от создателей DeepSeek) на уровне o3-mini (low).
Ну, и опять эксклюзив - на агентские задачи по кодингу, неожиданно вырвалась вперед моделька OpenHands LM 32B от ребят из OpenHands, которые дотренировали ее из Qwen Coder 2.5 Instruct 32B на своем "тренажере для агентов" SWE-Gym, опередив в итоге в SWE-bench даже огромную Deepseek V3 0324. В общем, OpenHands молодцы! Кстати, недавно их Code-агент взял новую соту (SoTA - State of The Art) в SWE-bench Verified. Так, что могу всем смело рекомендовать их блог.
Ух, ну и перенасытил я всех всего лишь одним абзацем!
В общем, что сказать-то хотел - ребята из Google посмотрели, значит, на свою Gemma 3 и увидели, что, при всей своей красоте, она довольно тяжелая все равно оказалась для консьюмерских ПК/GPU, ну и разразились они какой-то крутой квантизацией, которая называется QAT (Quantization-Aware Training). Что это за QAT такой мы тут разбираться не будем - просто для важно знать, что эта хитрая техника квантизации уменьшает требования моделей к железу до 4-х раз, при этом почти не влияя на уровень "интеллекта" модели.
Действительно ли это так? Давайте проверим на примере Gemma 12B IT QAT (4bit). Кстати, специальные MLX-квант-веса, оптимизированные для маководов (я) доступны по ссылке.
Так вот, моделька эта запускается через LMStudio в две кнопки.
В итоге, ответы действительно у нее неплохие, какую-то несложную кодогенерацию она явно вытянет. На, и русский язык ее оказался безупречным (см. скрины). Более того, после моего замечания она, как будто, даже вывезла задачу с генерацией параллельной генерации эмбеддингов (сама решила взять для этого SemaphoreSlim). С использованием Parallel уже не справилась, т. к. начала await юзать внутри Parallel.For (
А как у вас себя ведут локальные модельки? С какими задачами справляются, а с какими нет? И какие модели вы используете локально? (если вообще используете)