ZEROSEARCH: открытый фреймворк, снижающий затраты на обучение LLM поиску на 88%
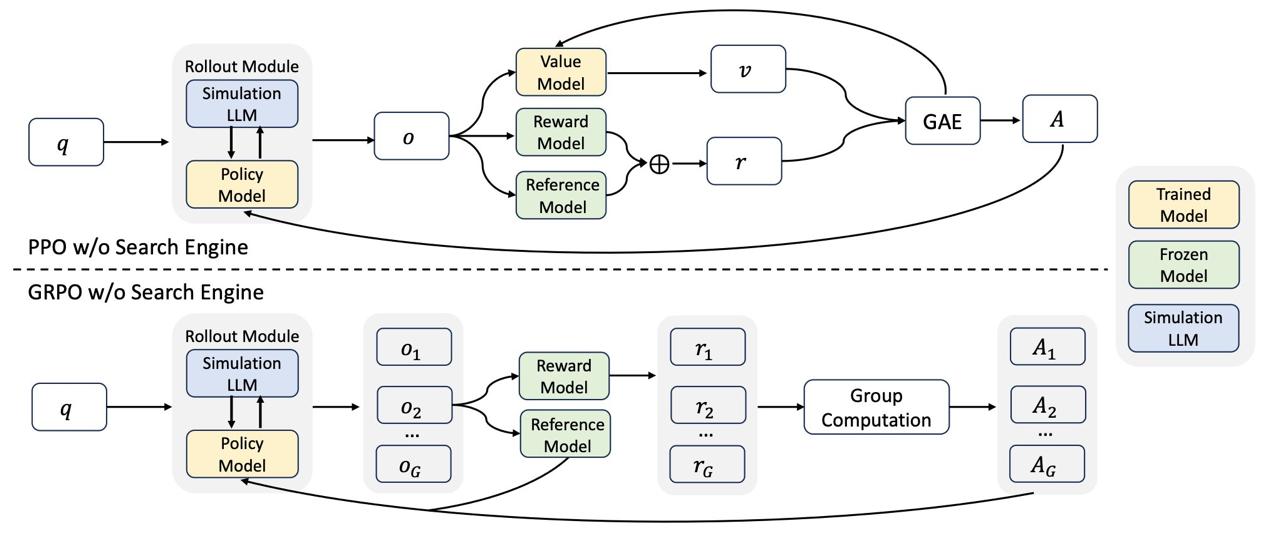
ZEROSEARCH основан на ключевом наблюдении: LLM уже приобрели обширные общие знания в процессе предварительного обучения и способны генерировать релевантные документы в ответ на поисковые запросы. Cвежие подходы сталкиваются с двумя проблемами: непредсказуемым качеством документов из поисковых систем и высокими затратами на API при обучении.
Фреймворк Zerosearch включает три ключевых компонента:
1. Симуляция поисковой системы: через supervised fine-tuning LLM генерирует как релевантные ответы, так и зашумленные документы путем изменения нескольких слов в промпте.
2. Во время RL-тренировки ZEROSEARCH использует стратегию curriculum-based rollout, которая постепенно снижает качество генерируемых документов. Подход последовательно развивает способность модели к рассуждению, прибегая ко всё более сложным сценариям.
3. Низкие затраты на обучение по сравнению с использованием коммерческих поисковых API. Реализация подхода требует GPU-инфраструктуры, но он снижает затраты на обучение на 88%.
В результате 7B-модель достигла производительности, сравнимой с использованием реальной поисковой системы для обучения. Модель с 14B параметров превосходит производительность модели, обученной на данных из реальной поисковой системы сразу на нескольких бенчмарках.
Исследователи опубликовали в открытом доступе реализацию кода, датасеты и предварительно обученные модели.
#StateoftheArt
ZEROSEARCH основан на ключевом наблюдении: LLM уже приобрели обширные общие знания в процессе предварительного обучения и способны генерировать релевантные документы в ответ на поисковые запросы. Cвежие подходы сталкиваются с двумя проблемами: непредсказуемым качеством документов из поисковых систем и высокими затратами на API при обучении.
Фреймворк Zerosearch включает три ключевых компонента:
1. Симуляция поисковой системы: через supervised fine-tuning LLM генерирует как релевантные ответы, так и зашумленные документы путем изменения нескольких слов в промпте.
2. Во время RL-тренировки ZEROSEARCH использует стратегию curriculum-based rollout, которая постепенно снижает качество генерируемых документов. Подход последовательно развивает способность модели к рассуждению, прибегая ко всё более сложным сценариям.
3. Низкие затраты на обучение по сравнению с использованием коммерческих поисковых API. Реализация подхода требует GPU-инфраструктуры, но он снижает затраты на обучение на 88%.
В результате 7B-модель достигла производительности, сравнимой с использованием реальной поисковой системы для обучения. Модель с 14B параметров превосходит производительность модели, обученной на данных из реальной поисковой системы сразу на нескольких бенчмарках.
Исследователи опубликовали в открытом доступе реализацию кода, датасеты и предварительно обученные модели.
#StateoftheArt