Seed-Coder 8B
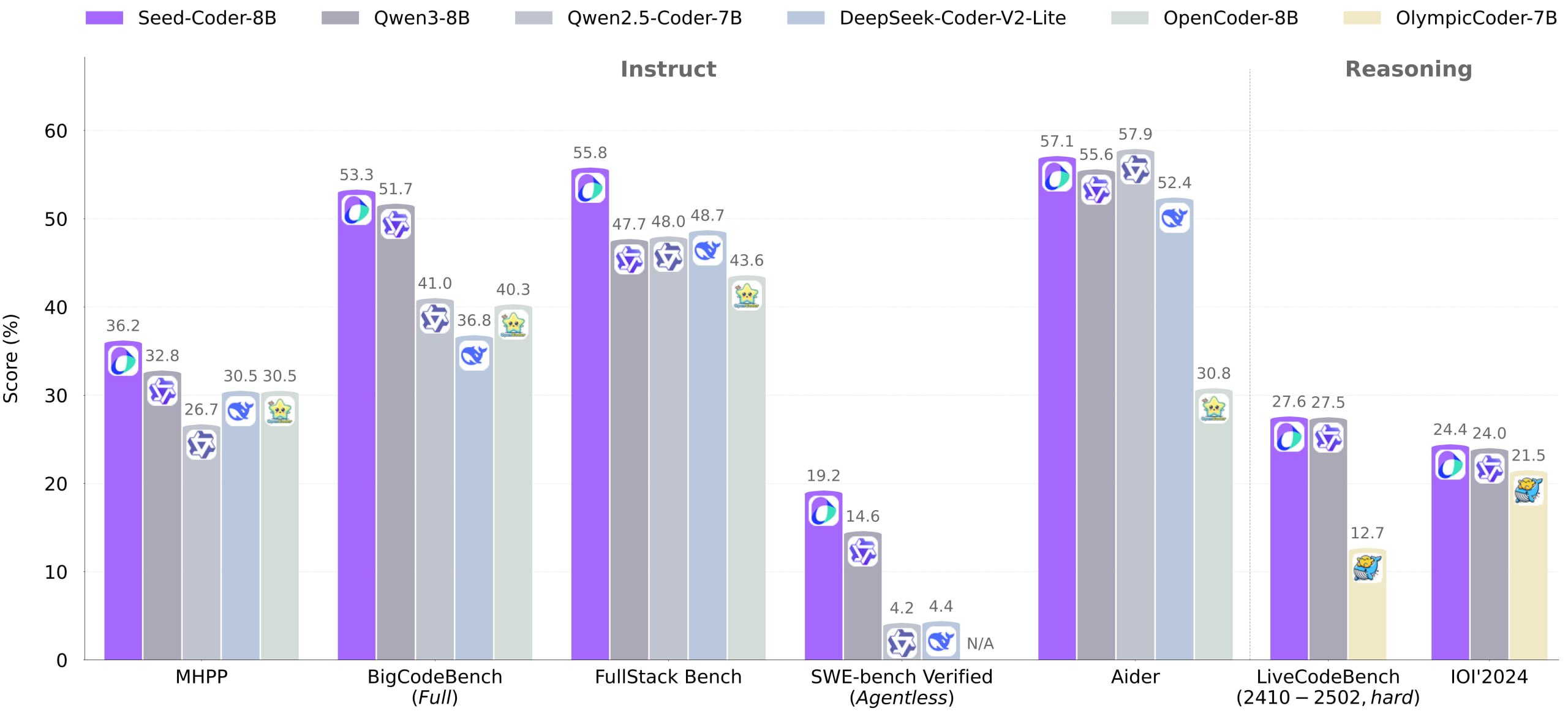
Лучшая в своей весовой категории LLM для кодинга, прямо от китайцев из Bytedance. Бьёт даже недавний Qwen 3 на коде, но даже не пытается конкурировать на других задачах. Кроме обычной инстракт модели натренировали и ризонер. При этом всём модель натренировали всего на 6 триллионах токенов, что крайне мало — датасеты лучших открытых моделей сейчас уже часто больше 30 триллионов токенов.
Ключевой элемент тренировки — "model-centric" пайплайн. Специальные LLM-фильтры оценивают код (читаемость, модульность и другие аспекты) из GitHub и веб-источников, отсеивая низкокачественные примеры. Таким образом они фильтруют данных примерно на ~2.3 триллиона токенов. Затем модель тренируют в течении 6 триллионах токенов, что даёт небольшую несостыковку. Скорее всего какие-то данные повторялись в датасете несколько раз, но авторы пейпера не говорят об этом напрямую.
Инстракт-версию тренируют через SFT (на синтетике, которую тоже LLM нагенерили и отфильтровали) и DPO. Ризонинг-модель дрессируют через LongCoT RL, чтобы она лучше решала сложные задачки. Итог: Seed-Coder рвёт опенсорс-аналоги своего размера на бенчмарках (генерация, автодополнение, ризонинг и т.д.), а местами и более жирные модели.
Веса: Reasoner/Instruct
Техрепорт
@ai_newz
Лучшая в своей весовой категории LLM для кодинга, прямо от китайцев из Bytedance. Бьёт даже недавний Qwen 3 на коде, но даже не пытается конкурировать на других задачах. Кроме обычной инстракт модели натренировали и ризонер. При этом всём модель натренировали всего на 6 триллионах токенов, что крайне мало — датасеты лучших открытых моделей сейчас уже часто больше 30 триллионов токенов.
Ключевой элемент тренировки — "model-centric" пайплайн. Специальные LLM-фильтры оценивают код (читаемость, модульность и другие аспекты) из GitHub и веб-источников, отсеивая низкокачественные примеры. Таким образом они фильтруют данных примерно на ~2.3 триллиона токенов. Затем модель тренируют в течении 6 триллионах токенов, что даёт небольшую несостыковку. Скорее всего какие-то данные повторялись в датасете несколько раз, но авторы пейпера не говорят об этом напрямую.
Инстракт-версию тренируют через SFT (на синтетике, которую тоже LLM нагенерили и отфильтровали) и DPO. Ризонинг-модель дрессируют через LongCoT RL, чтобы она лучше решала сложные задачки. Итог: Seed-Coder рвёт опенсорс-аналоги своего размера на бенчмарках (генерация, автодополнение, ризонинг и т.д.), а местами и более жирные модели.
Веса: Reasoner/Instruct
Техрепорт
@ai_newz