Как сэкономить до 4 раз на длинных промптах в OpenAI API
Если ваш стартап, продукт или сервис часто отправляет в OpenAI один и тот же системный промпт, вы можете существенно сократить расходы благодаря функции кеширования (Prompt Caching). Интересно, что многие об этом не знают и не используют эту возможность в полной мере. Хотя мы про это рассказывали тут.
Что это такое?
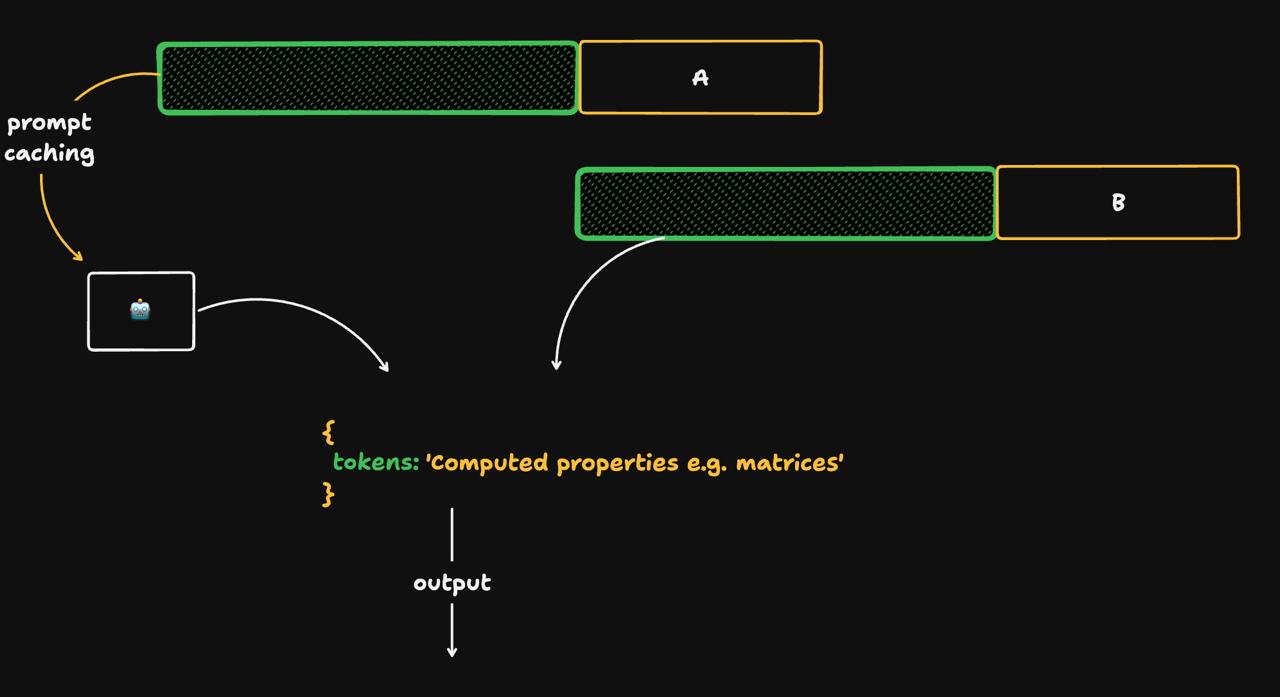
OpenAI автоматически кеширует начало промпта (префикс), если оно уже обрабатывалось недавно. Это позволяет избежать повторного вычисления при каждом запросе.
Результат:
– Задержка может снизиться до 80%😱
– Стоимость токенов для префикса — до 50%😱
Когда работает кеш?
– Срабатывает, если промпт длиннее 1024 токенов.
– Проверяется, использовался ли этот префикс недавно.
– Время жизни кеша — от 5 до 10 минут, иногда до часа (если не было запросов, кеш очищается).
Эта функция нереально полезна, когда отправляется много запросов с одинаковым началом. Вангую, ваш случай подходит, даже если у вас RAG 🦞
Что считается совпадением?
Промпт должен совпадать с точностью до символа: пробелы, порядок строк и даже кавычки имеют значение. Кеш работает блоками: 1024, 1152, 1280 токенов и далее с шагом 128 токенов (в зависимости от длины вашего входного промпта).
Что кешируется?
– System-промпт
– Инструкции, примеры, структура вывода
– Список инструментов
– Изображения (когда они передаются в формате base64 и если они одинаковые каждый раз)
Важно: все эти элементы должны находиться в начале промпта.
Как понять, что кеш сработал?
Обратите внимание на поле
Нужно ли что-то включать?
Нет. Кеш работает автоматически, без дополнительных настроек и доплат. Он встроен во все модели, начиная с gpt-4.
Рекомендации:
– Фиксируйте начало промпта (префикс должен оставаться статичным).
– Избегайте мелких правок и случайных изменений.
– Динамический контент размещайте в конце.
Если вы работаете с длинными и повторяющимися промптами, кеширование is all you need😉
🎚️ Подробнее о кешировании в OpenAI API можно прочитать здесь.
Если ваш стартап, продукт или сервис часто отправляет в OpenAI один и тот же системный промпт, вы можете существенно сократить расходы благодаря функции кеширования (Prompt Caching). Интересно, что многие об этом не знают и не используют эту возможность в полной мере. Хотя мы про это рассказывали тут.
Что это такое?
OpenAI автоматически кеширует начало промпта (префикс), если оно уже обрабатывалось недавно. Это позволяет избежать повторного вычисления при каждом запросе.
Результат:
– Задержка может снизиться до 80%
– Стоимость токенов для префикса — до 50%
Когда работает кеш?
– Срабатывает, если промпт длиннее 1024 токенов.
– Проверяется, использовался ли этот префикс недавно.
– Время жизни кеша — от 5 до 10 минут, иногда до часа (если не было запросов, кеш очищается).
Эта функция нереально полезна, когда отправляется много запросов с одинаковым началом. Вангую, ваш случай подходит, даже если у вас RAG 🦞
Что считается совпадением?
Промпт должен совпадать с точностью до символа: пробелы, порядок строк и даже кавычки имеют значение. Кеш работает блоками: 1024, 1152, 1280 токенов и далее с шагом 128 токенов (в зависимости от длины вашего входного промпта).
Что кешируется?
– System-промпт
– Инструкции, примеры, структура вывода
– Список инструментов
– Изображения (когда они передаются в формате base64 и если они одинаковые каждый раз)
Важно: все эти элементы должны находиться в начале промпта.
Как понять, что кеш сработал?
Обратите внимание на поле
cached_tokens в ответе API. Если значение больше нуля, это означает, что часть промпта была взята из кеша.Нужно ли что-то включать?
Нет. Кеш работает автоматически, без дополнительных настроек и доплат. Он встроен во все модели, начиная с gpt-4.
Рекомендации:
– Фиксируйте начало промпта (префикс должен оставаться статичным).
– Избегайте мелких правок и случайных изменений.
– Динамический контент размещайте в конце.
Если вы работаете с длинными и повторяющимися промптами, кеширование is all you need