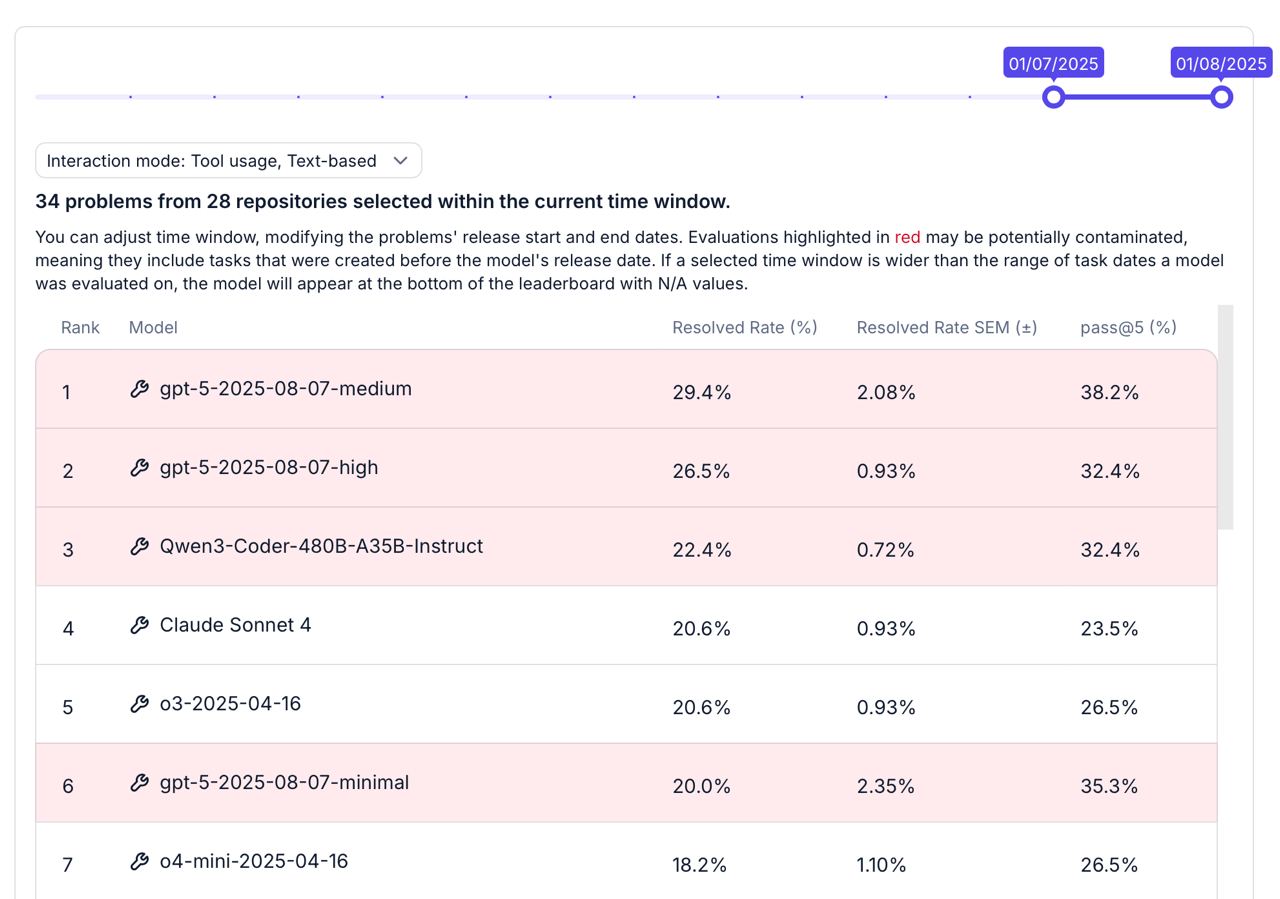
Продолжаем обновлять swe-rebench leaderboard, и вчера туда на первое место ворвалась gpt5 с medium reasoning effort. Хочется на этот счет оставить пару комментариев:
1. Как видно из лидерборда, medium effort стоит выше high. Связано это как минимум отчасти с тем, что с high effort модель получается чересчур саморефлексирующей, то есть постоянно перепроверяет себя, повторно тестирует решение и в конце концов упирается в лимит по кол-ву шагов (сейчас это 80).
2. Запуск использовал completions эндпоинт, а с ним есть проблема: ризонинг модели нельзя подать на вход следующего терна, поэтому на каждом шаге модель видит аутпут + тул, но не рассуждения.
Если первый пункт остается под вопросом, то второй мы поправим в ближайшее время. Глобально это означает, что результаты gpt5 могут быть еще выше.
Подробнее про rebench: https://t.me/AIexTime/121
1. Как видно из лидерборда, medium effort стоит выше high. Связано это как минимум отчасти с тем, что с high effort модель получается чересчур саморефлексирующей, то есть постоянно перепроверяет себя, повторно тестирует решение и в конце концов упирается в лимит по кол-ву шагов (сейчас это 80).
2. Запуск использовал completions эндпоинт, а с ним есть проблема: ризонинг модели нельзя подать на вход следующего терна, поэтому на каждом шаге модель видит аутпут + тул, но не рассуждения.
Если первый пункт остается под вопросом, то второй мы поправим в ближайшее время. Глобально это означает, что результаты gpt5 могут быть еще выше.
Подробнее про rebench: https://t.me/AIexTime/121