Новая новая моделька от DeepSeek для интересующихся.
Модель тренировали свежей V3.1-Terminus, но слегка изменив механизм внимания, DeepSeek Sparse Attention. Если очень вкратце, то теперь каждый токен обращает внимание на 2048 других, а не все предыдущие, и на основе слегка по-другому посчитанного произведения Q и K. Замена уже применявшегося механизма на новый не требует обучения с нуля — V3.2 это та же V3.1, дообученная на примерно триллионе токенов.
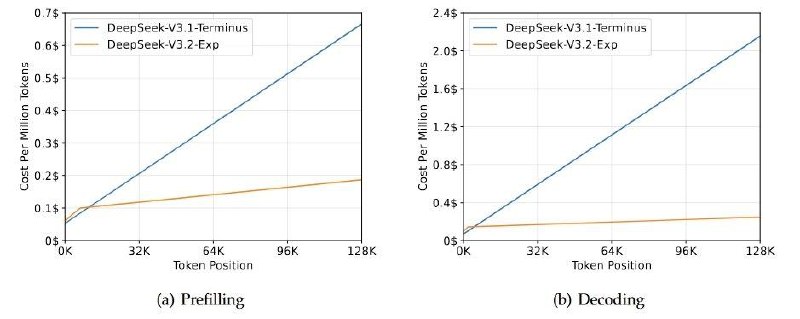
Получается существенно снизить затраты на поддержание длинного контекста — что очень важно в эпоху рассуждающих моделей; Я думаю, что скорее всего главная причина движения в этом направлении — более длинные цепочки рассуждений для задач, требующих сотни вызовов инструментов.
За миллион сгенерированных токенов у новой модели будут просить $0.42 (вместо $1.68 на V3.1).
По метрикам показывают, что качество не страдает.
Статья с техническими подробностями того, как работает новый Attention, тут.
Модель тренировали свежей V3.1-Terminus, но слегка изменив механизм внимания, DeepSeek Sparse Attention. Если очень вкратце, то теперь каждый токен обращает внимание на 2048 других, а не все предыдущие, и на основе слегка по-другому посчитанного произведения Q и K. Замена уже применявшегося механизма на новый не требует обучения с нуля — V3.2 это та же V3.1, дообученная на примерно триллионе токенов.
Получается существенно снизить затраты на поддержание длинного контекста — что очень важно в эпоху рассуждающих моделей; Я думаю, что скорее всего главная причина движения в этом направлении — более длинные цепочки рассуждений для задач, требующих сотни вызовов инструментов.
За миллион сгенерированных токенов у новой модели будут просить $0.42 (вместо $1.68 на V3.1).
По метрикам показывают, что качество не страдает.
Статья с техническими подробностями того, как работает новый Attention, тут.