DeepSeek выпустили новую модель DeepSeek-V3.2-Exp
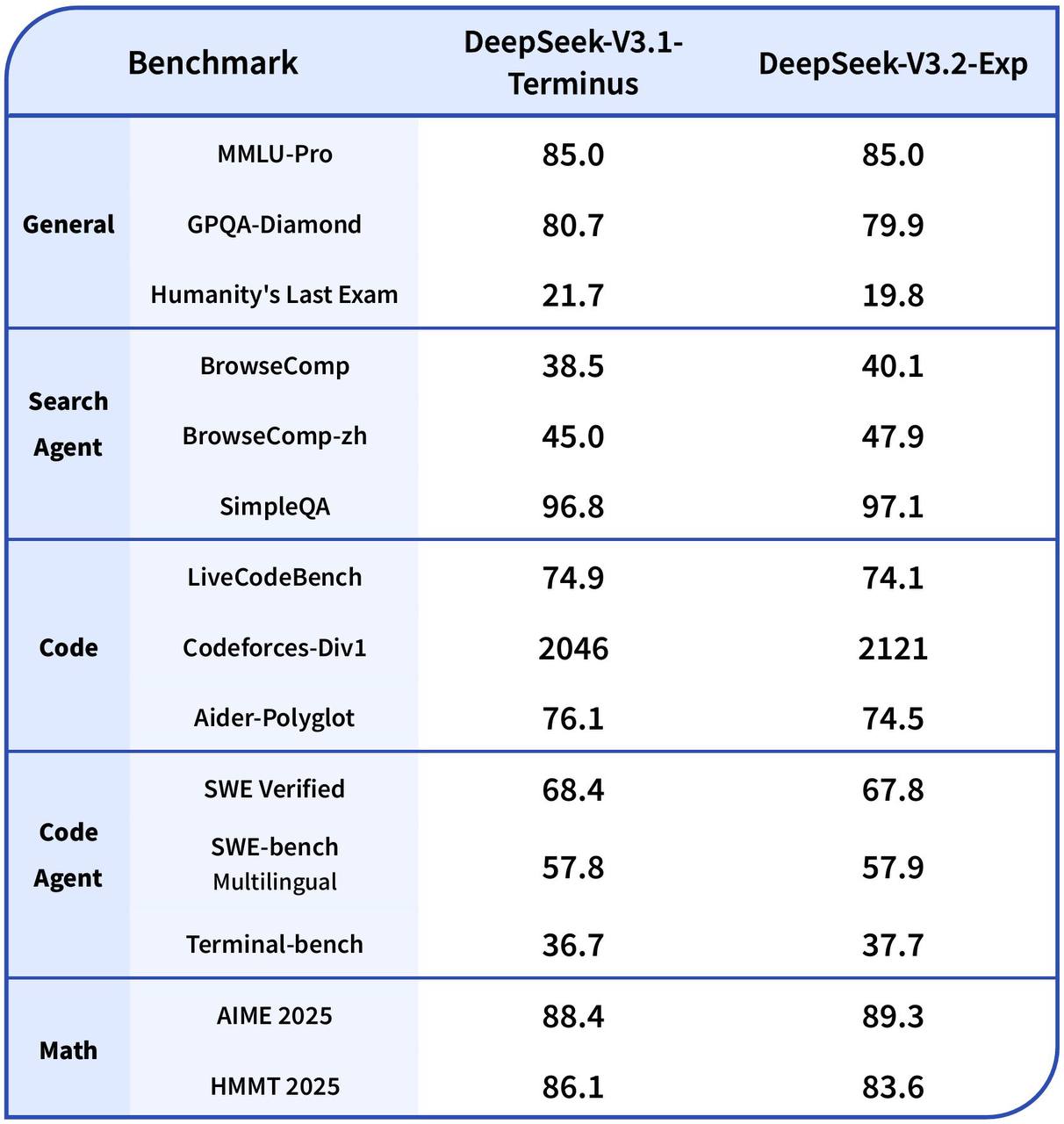
Качество примерно на уровне предыдущей DeepSeek-V3.1 Terminus, а цена стала на 50+% ниже.
Основное нововведение, за счет которого и удалось снизить косты и повысить скорость, – DeepSeek Sparse Attention(DSA). Не отходя от кассы на второй картинке можете посмотреть, насколько он оптимизирует стоимость на длинных последовательностях.
DSA – это специальная вариация механизма внимания, которая позволяет вычислять аттеншен не на всех парах токенах, а избирательно.
В большинстве вариантов Sparse Attention маска для всех запросов совпадает (грубо говоря, все токены смотрят на одинаковые позиции), но здесь заявляется fine-grained. То есть маска формируется динамически для каждого токена, так что модель не теряет важные зависимости, и качество почти не падает.
Ну а ускорение получается за счет того, что сложность алгоритма уже не квадратичная по длине последовательности, а линейная.
Моделька уже доступна в приложении, в вебе и в API
Веса | Техрепорт
Качество примерно на уровне предыдущей DeepSeek-V3.1 Terminus, а цена стала на 50+% ниже.
Основное нововведение, за счет которого и удалось снизить косты и повысить скорость, – DeepSeek Sparse Attention(DSA). Не отходя от кассы на второй картинке можете посмотреть, насколько он оптимизирует стоимость на длинных последовательностях.
DSA – это специальная вариация механизма внимания, которая позволяет вычислять аттеншен не на всех парах токенах, а избирательно.
В большинстве вариантов Sparse Attention маска для всех запросов совпадает (грубо говоря, все токены смотрят на одинаковые позиции), но здесь заявляется fine-grained. То есть маска формируется динамически для каждого токена, так что модель не теряет важные зависимости, и качество почти не падает.
Ну а ускорение получается за счет того, что сложность алгоритма уже не квадратичная по длине последовательности, а линейная.
Моделька уже доступна в приложении, в вебе и в API
Веса | Техрепорт