В Cursor обновили модель поиска: благодаря RAG многое теперь работает лучше
В Cursor уже давно используется retrieval-механика: агент ищет по кодовой базе и добавляет нужные куски в контекст LLM. Но раньше был реализован просто grep вариант – поиск по строковому совпадению. Это быстро, но не всегда в достаточной степени релевантно.
Теперь же ему на смену пришел более умный семантический поиск. По сути, RAG. То есть релевантность кусочков кода теперь оценивает специальная векторная модель, которая уже не просто ищет по ключевым словам, а сопоставляет смыслы.
Интересно, что для этого обновления Cursor обучили собственную embedding-модель, заточенную именно под код. Для этого использовались реальные траектории работы агента. Каждая сессия – это последовательность: запрос -> поиск релевантных кусочков кода -> результат. Отдельная LLM-ка по этим траекториям оценивала, какие из найденных кусочков в итоге пригодились, а какие оказались шумом.
А дальше берем нашу векторную модель и учим ее на триплетах (запрос, релевантные файлы, нерелевантные) так, чтобы в итоге ее ранжирование соответствовало ранжированию LLM, то есть более полезные кусочки были в векторном пространстве ближе к запросу.
Grep-поиск, кстати, все еще где-то остается: например, он незаменим, когда надо быстро поискать по названиям переменных или функций. Результаты grep-модуля и векторной модельки комбинируются.
Что в итоге с метриками:
1. На оффлайн-оценке на специально собранном бенчмарке «Cursor Context Bench» среднее повышение точности составило ~12,5%.
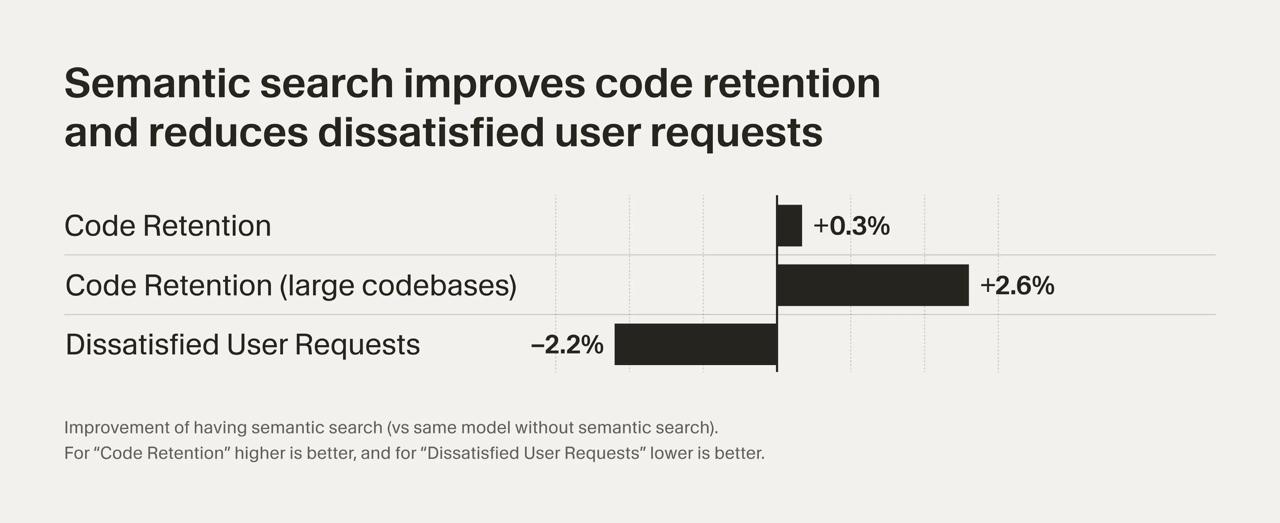
2. На A/B-тестах в среднем на ~0,3% вырос code retention. Это метрика, показывающая, сколько кода, сгенерированного агентом, в итоге осталось в проекте пользователя спустя время. На больших кодовых базах наблюдалось вообще +2,6%.
3. Также на ~2,2% понизилось количество dissatisfied follow-up requests – когда пользователь вынужден делать исправления или дополнительные запросы, если у агента что-то не вышло с первого раза.
Эффект не огромный, потому что далеко не каждый запрос вообще треубует поиска, но он есть и особенно будет ощущаться в крупных кодовых базах.
https://cursor.com/blog/semsearch
В Cursor уже давно используется retrieval-механика: агент ищет по кодовой базе и добавляет нужные куски в контекст LLM. Но раньше был реализован просто grep вариант – поиск по строковому совпадению. Это быстро, но не всегда в достаточной степени релевантно.
Теперь же ему на смену пришел более умный семантический поиск. По сути, RAG. То есть релевантность кусочков кода теперь оценивает специальная векторная модель, которая уже не просто ищет по ключевым словам, а сопоставляет смыслы.
Интересно, что для этого обновления Cursor обучили собственную embedding-модель, заточенную именно под код. Для этого использовались реальные траектории работы агента. Каждая сессия – это последовательность: запрос -> поиск релевантных кусочков кода -> результат. Отдельная LLM-ка по этим траекториям оценивала, какие из найденных кусочков в итоге пригодились, а какие оказались шумом.
А дальше берем нашу векторную модель и учим ее на триплетах (запрос, релевантные файлы, нерелевантные) так, чтобы в итоге ее ранжирование соответствовало ранжированию LLM, то есть более полезные кусочки были в векторном пространстве ближе к запросу.
Grep-поиск, кстати, все еще где-то остается: например, он незаменим, когда надо быстро поискать по названиям переменных или функций. Результаты grep-модуля и векторной модельки комбинируются.
Что в итоге с метриками:
1. На оффлайн-оценке на специально собранном бенчмарке «Cursor Context Bench» среднее повышение точности составило ~12,5%.
2. На A/B-тестах в среднем на ~0,3% вырос code retention. Это метрика, показывающая, сколько кода, сгенерированного агентом, в итоге осталось в проекте пользователя спустя время. На больших кодовых базах наблюдалось вообще +2,6%.
3. Также на ~2,2% понизилось количество dissatisfied follow-up requests – когда пользователь вынужден делать исправления или дополнительные запросы, если у агента что-то не вышло с первого раза.
Эффект не огромный, потому что далеко не каждый запрос вообще треубует поиска, но он есть и особенно будет ощущаться в крупных кодовых базах.
https://cursor.com/blog/semsearch