Google выпустили статью про SIMA-2. Оказалось, что агент способен на самообучение.
SIMA-2 – это ИИ-агент для игр. Первая его версия вышла примерно полтора года назад, вторую релизнули в ноябре, но статью выложили только сейчас.
Апгрейднули SIMA-2 относительно первой SIMA довольно сильно: теперь модель способна рассуждать и генерализоваться на новые игры, а не просто механически выполнять какие-то действия.
Особой магии под капотом нет – по сути, это дотюненная на игровые действия Gemini Flash-Lite. В статье, конечно, много занятных деталей про обучение, но самое интересное, на наш взгляд, спрятано в разделе про self-improvement.
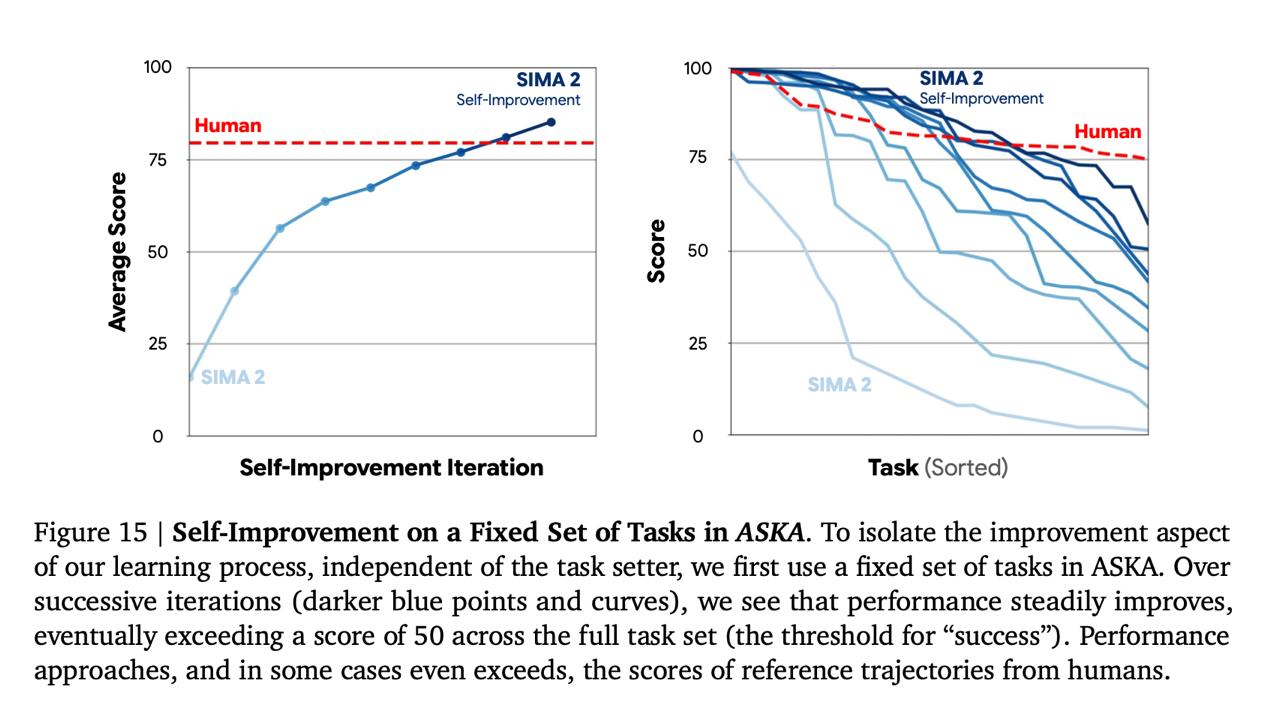
Исследователи попробовали поместить агента в совершенно новую для него игру ASKA, не дали никаких инструкций или человеческих демонтраций, и запустили процесс самоулучшения.
Агент (внутри которого, напоминаем, сидит LLM) был сам себе тестировщиком, исполнителем и reward-моделькой. Один экземпляр Gemini – Task setter – придумывал задачку нужного уровня -> SIMA пробовал ее исполнять -> другой экземпляр Gemini оценивал успех -> на основе этого фидбэка обновлялась политика -> и так много-много итераций с постепенным усложнением задач.
В итоге в игре, которую агент никогда не видел, дообученная таким образом система превзошла не только исходную SIMA-2, но и человека! И это буквально полностью автономное обучение на основе собственного опыта.
Какой-то RL-v2
Советуем почитать полностью: arxiv.org/pdf/2512.04797
SIMA-2 – это ИИ-агент для игр. Первая его версия вышла примерно полтора года назад, вторую релизнули в ноябре, но статью выложили только сейчас.
Апгрейднули SIMA-2 относительно первой SIMA довольно сильно: теперь модель способна рассуждать и генерализоваться на новые игры, а не просто механически выполнять какие-то действия.
Особой магии под капотом нет – по сути, это дотюненная на игровые действия Gemini Flash-Lite. В статье, конечно, много занятных деталей про обучение, но самое интересное, на наш взгляд, спрятано в разделе про self-improvement.
Исследователи попробовали поместить агента в совершенно новую для него игру ASKA, не дали никаких инструкций или человеческих демонтраций, и запустили процесс самоулучшения.
Агент (внутри которого, напоминаем, сидит LLM) был сам себе тестировщиком, исполнителем и reward-моделькой. Один экземпляр Gemini – Task setter – придумывал задачку нужного уровня -> SIMA пробовал ее исполнять -> другой экземпляр Gemini оценивал успех -> на основе этого фидбэка обновлялась политика -> и так много-много итераций с постепенным усложнением задач.
В итоге в игре, которую агент никогда не видел, дообученная таким образом система превзошла не только исходную SIMA-2, но и человека! И это буквально полностью автономное обучение на основе собственного опыта.
Какой-то RL-v2
Советуем почитать полностью: arxiv.org/pdf/2512.04797