Atomic Semaphore
Пока я мучаюсь с поиском адаптивного инструмента для определения оптимального кол-ва потоков в пулах, получилось поиграть с реализацией семафора на атомиках.
Как мы все понимаем, семафор можно реализовать не только через каналы.
Например:
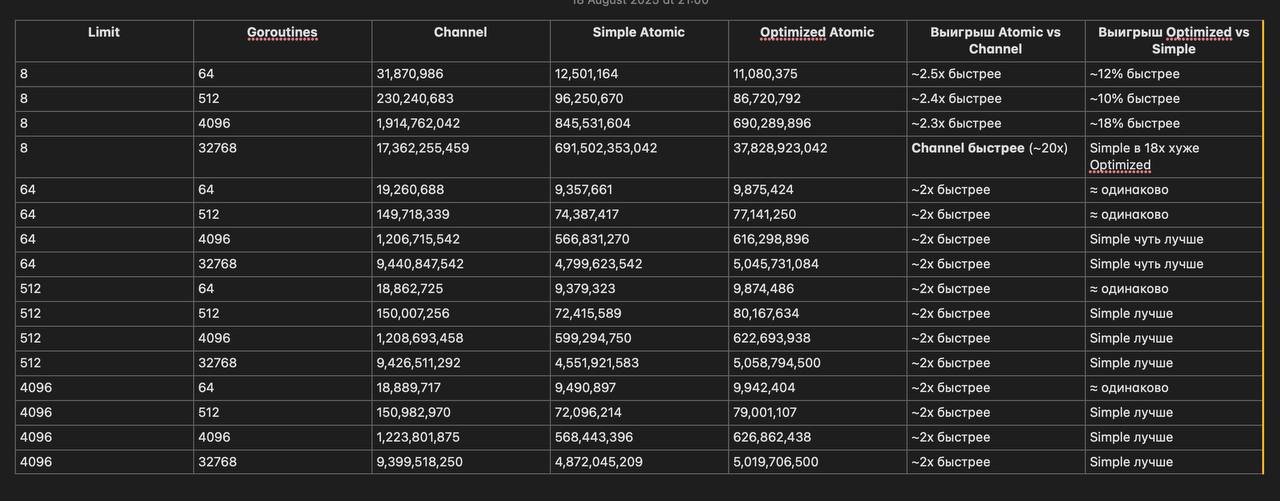
Но бенчи показали, что все не так очевидно. Я попробовала запускать channel, simple atomic и оптимизированный atomic на разных комбинациях лимитов семафора и запускаемых горутин (например limit 8 + 4096 горутин; limit 64 + 32768)
Выводы по результатам тестирования такие:
- Канальный семафор сильно проигрывает атомикам почти во всех сценариях: задержки в 2–3 раза выше, а при росте горутин — до 10x хуже.
Это объяснимо — каналы используют более тяжёлый sync-механизм и связаны с планировкой.
- Simple Atomic в среднем даёт наилучшее время при больших лимитах (64–4096).
Его преимущество перед Channel почти везде стабильно ~2x.
- Оптимизированный Atomic показывает себя лучше на малых лимитах и высокой конкуренции (например, Limit=8, Goroutines=4096: выигрыш примерно 18%).
Но на больших лимитах и особенно при десятках тысяч горутин он хуже Simple Atomic, т.к. спин + backoff начинают мешать.
Но есть и аномалия (например на Limit=8, Goroutines=32768):
Простой atomic показываем резкий провал (691 млрд ns/op).
Оптимизированный atomic дал 38 млрд ns/op, что всё равно в 2x хуже канальных (17 млрд).
Возможно, причина в сильнейшем contention при очень низком лимите и огромном числе горутин. Должно быть каналы выигрывают за счёт встроенной очереди и блокировки
Из рекомендаций можно выделить такое:
- Для малых лимитов (например меньше 64) и числа горутин около 4k - можно выбирать оптимизированный Atomic на CAS + backoff.
- Для больших лимитов (>64) - простой Atomic, почему то он повел себя лучше оптимизированного.
- Для малых лимитов и десятков тысяч горутин - ну, канал показал результаты лучше всех...
Вот и думайте…
Пока я мучаюсь с поиском адаптивного инструмента для определения оптимального кол-ва потоков в пулах, получилось поиграть с реализацией семафора на атомиках.
Как мы все понимаем, семафор можно реализовать не только через каналы.
Например:
type Sem struct {
limit int32
cur *atomic.Int32
}
func NewSem(init int) *Sem {
return &Sem{
limit: int32(init),
cur: &atomic.Int32{},
}
}
func (s *Sem) TryAcquire() bool {
for {
cur := s.cur.Load()
if cur >= s.limit {
return false
}
if s.cur.CompareAndSwap(cur, cur+1) {
return true
}
}
}
func (s *Sem) Release() {
cur := s.cur.Add(-1)
if cur < 0 {
panic("semaphore release without acquire")
}
}
Базовый бенч с limit=50 при 200 горутинах показал, что AtomicSem быстрее ChannelSem примерно в 2 раза:
goos: darwin
goarch: arm64
pkg: go-helloworld/semaphore
cpu: Apple M3 Pro
BenchmarkAtomicSem
BenchmarkAtomicSem-11 42 28481842 ns/op
BenchmarkChannelSem
BenchmarkChannelSem-11 19 59474664 ns/op
PASS
Но данное решение плохо работает с большим количеством потоков, так как будет больше конкуренция на CAS loop операции между потоками -> получаем деградацию CAS
Решение:
- Добавить fast check load - завершаем функцию если лимит уже превышен
- Потом быстрый спин-цикл (напр 302 итераций) с CAS + добавить runtime.Gosched(), чтобы горутина переодически снимала себя с потока
- Если спины не дали результата - делать exponential backoff (time.Sleep) до х50
Пример:
func (s *Sem) OptimizedTryAcquire() bool {
// Быстрая проверка если уже заполнено
if s.cur.Load() >= s.limit {
return false
}
// Короткий спин с CAS
const spinCount = 302
for i := 0; i < spinCount; i++ {
cur := s.cur.Load()
if cur >= s.limit {
return false
}
if s.cur.CompareAndSwap(cur, cur+1) {
return true
}
// периодически снимаем горутину через goshed
if (i & 7) == 0 {
runtime.Gosched()
}
}
// Экспоненциальный backoff
backoff := 1 * time.Microsecond
const maxBackoff = 50 * time.Millisecond
for {
// до сна проверяем — возможно место освободилось
cur := s.cur.Load()
if cur >= s.limit {
return false
}
if s.cur.CompareAndSwap(cur, cur+1) {
return true
}
time.Sleep(backoff)
backoff *= 2
if backoff > maxBackoff {
backoff = maxBackoff
}
}
}{}
Но бенчи показали, что все не так очевидно. Я попробовала запускать channel, simple atomic и оптимизированный atomic на разных комбинациях лимитов семафора и запускаемых горутин (например limit 8 + 4096 горутин; limit 64 + 32768)
Выводы по результатам тестирования такие:
- Канальный семафор сильно проигрывает атомикам почти во всех сценариях: задержки в 2–3 раза выше, а при росте горутин — до 10x хуже.
Это объяснимо — каналы используют более тяжёлый sync-механизм и связаны с планировкой.
- Simple Atomic в среднем даёт наилучшее время при больших лимитах (64–4096).
Его преимущество перед Channel почти везде стабильно ~2x.
- Оптимизированный Atomic показывает себя лучше на малых лимитах и высокой конкуренции (например, Limit=8, Goroutines=4096: выигрыш примерно 18%).
Но на больших лимитах и особенно при десятках тысяч горутин он хуже Simple Atomic, т.к. спин + backoff начинают мешать.
Но есть и аномалия (например на Limit=8, Goroutines=32768):
Простой atomic показываем резкий провал (691 млрд ns/op).
Оптимизированный atomic дал 38 млрд ns/op, что всё равно в 2x хуже канальных (17 млрд).
Возможно, причина в сильнейшем contention при очень низком лимите и огромном числе горутин. Должно быть каналы выигрывают за счёт встроенной очереди и блокировки
Из рекомендаций можно выделить такое:
- Для малых лимитов (например меньше 64) и числа горутин около 4k - можно выбирать оптимизированный Atomic на CAS + backoff.
- Для больших лимитов (>64) - простой Atomic, почему то он повел себя лучше оптимизированного.
- Для малых лимитов и десятков тысяч горутин - ну, канал показал результаты лучше всех...
Вот и думайте…