Cursor давно использует retrieval-механику, где агент ищет по кодовой базе и добавляет нужные фрагменты в контекст LLM
Теперь используется семантический поиск на основе RAG
Cursor обучил собственную embedding-модель, специализированную для кода, используя реальные траектории работы агента. LLM оценивала, какие фрагменты кода оказались полезными, а какие — шумом.
Векторная модель обучалась на триплетах (запрос, релевантные файлы, нерелевантные) так, чтобы её ранжирование соответствовало оценкам LLM, приближая полезные фрагменты к запросу в векторном пространстве.
Grep-поиск остался для быстрого поиска по названиям переменных и функций. Результаты grep-модуля и векторной модели комбинируются.
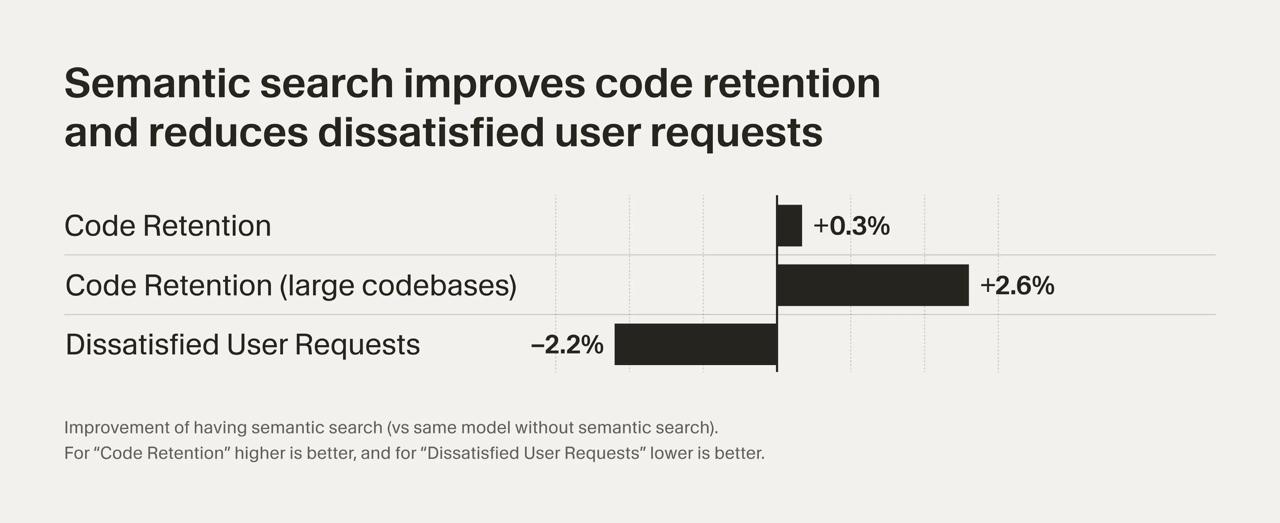
**Метрики:**
1. На бенчмарке «Cursor Context Bench» точность поиска повысилась на ~12,5%.
2. На A/B-тестах code retention
3. Количество dissatisfied follow-up requests снизилось на ~2,2%.
Эффект заметен, особенно в крупных кодовых базах.
LLM (Large Language Model) — большая языковая модель.
. Ранее применялся простой grep-поиск по строковому совпадению, что было быстро, но не всегда достаточно релевантно.Теперь используется семантический поиск на основе RAG
RAG (Retrieval-Augmented Generation) — метод, при котором LLM дополняется информацией, полученной из внешних источников.
. Релевантность кода оценивается векторной моделью, сопоставляющей смыслы, а не просто ключевые слова.Cursor обучил собственную embedding-модель, специализированную для кода, используя реальные траектории работы агента. LLM оценивала, какие фрагменты кода оказались полезными, а какие — шумом.
Векторная модель обучалась на триплетах (запрос, релевантные файлы, нерелевантные) так, чтобы её ранжирование соответствовало оценкам LLM, приближая полезные фрагменты к запросу в векторном пространстве.
Grep-поиск остался для быстрого поиска по названиям переменных и функций. Результаты grep-модуля и векторной модели комбинируются.
**Метрики:**
1. На бенчмарке «Cursor Context Bench» точность поиска повысилась на ~12,5%.
2. На A/B-тестах code retention
Code retention — метрика, показывающая, сколько сгенерированного кода остаётся в проекте пользователя.
вырос в среднем на ~0,3%, а на больших кодовых базах — на +2,6%.3. Количество dissatisfied follow-up requests снизилось на ~2,2%.
Эффект заметен, особенно в крупных кодовых базах.