Google выпустила подробную статью о своем новом достижении в области искусственного интеллекта — агенте SIMA-2. Самое примечательное в нем — способность к автономному самообучению.
SIMA-2 — это специализированный ИИ-агент, предназначенный для игр. Первая версия была представлена около полутора лет назад, а вторая вышла в ноябре прошлого года. Однако детали и результаты исследований, о которых идет речь, были опубликованы только сейчас.
Значительные улучшения SIMA-2 по сравнению с первой версией включают способность к более глубокому рассуждению и умению генерализоваться, то есть применять полученные знания в совершенно новых для него играх, а не просто выполнять заученные механические действия.
Технологически, SIMA-2 не содержит революционной "магии": по сути, это доработанная и оптимизированная для игровых задач версия модели Gemini Flash-Lite. Хотя статья изобилует интересными подробностями об обучении, ключевой прорыв, по мнению исследователей, кроется в разделе, посвященном самосовершенствованию (self-improvement).
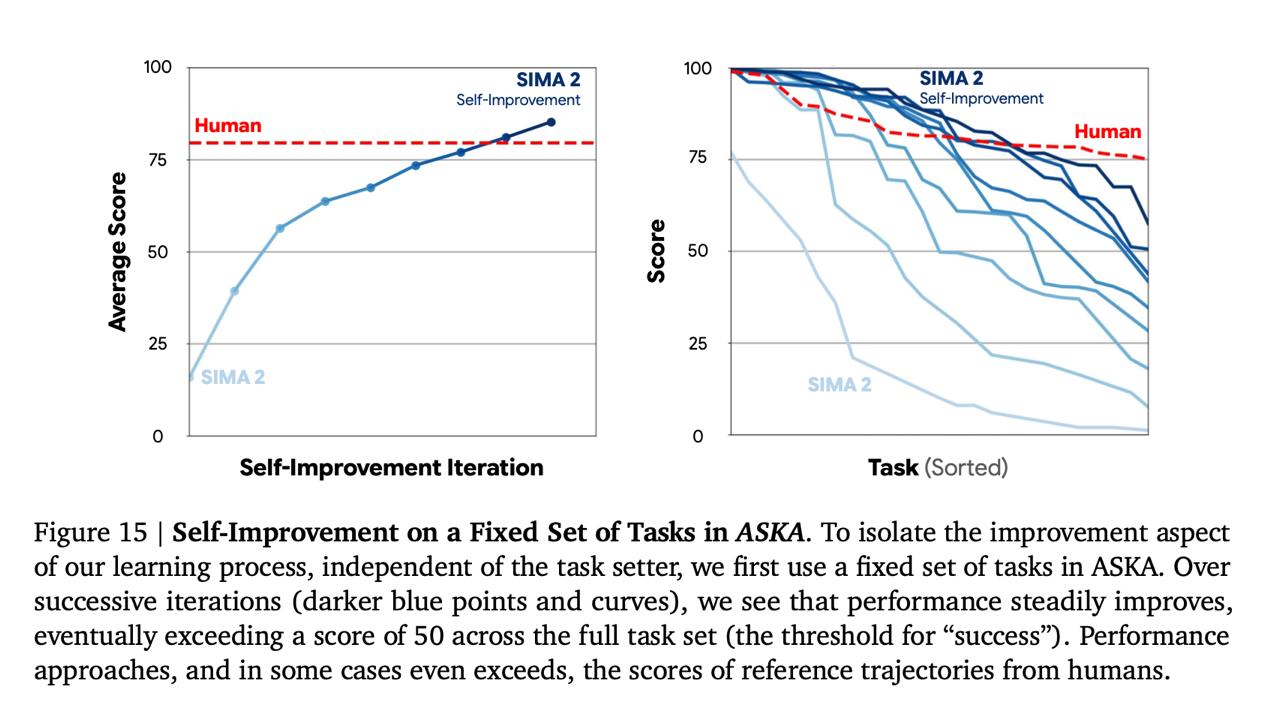
Чтобы протестировать эту функцию, ученые поместили агента в совершенно новую для него игру под названием ASKA. Агенту не давали никаких предварительных инструкций или демонстраций действий человека. Затем был запущен процесс автономного самоулучшения.
В этой системе агент, оснащенный большой языковой моделью (LLM), играл несколько ролей одновременно: он был и тестировщиком, и исполнителем задач, и даже моделью для оценки вознаграждения (reward model). Один экземпляр Gemini, названный "Task setter", отвечал за придумывание заданий соответствующего уровня сложности. SIMA-2 пытался выполнить эти задачи, а затем другой экземпляр Gemini оценивал успех или неудачу. На основе этой обратной связи обновлялась политика поведения агента. Этот итеративный процесс повторялся множество раз, постепенно усложняя задачи.
Результаты эксперимента поразительны: в игре, которую агент никогда прежде не видел, дообученная таким образом система не только превзошла исходную версию SIMA-2, но и показала лучшие результаты, чем человек! Это демонстрирует полностью автономное обучение, основанное исключительно на собственном опыте агента.
По сути, это напоминает новый уровень развития Reinforcement Learning
Для более глубокого погружения в тему, советуем ознакомиться с полной статьей: arxiv.org/pdf/2512.04797