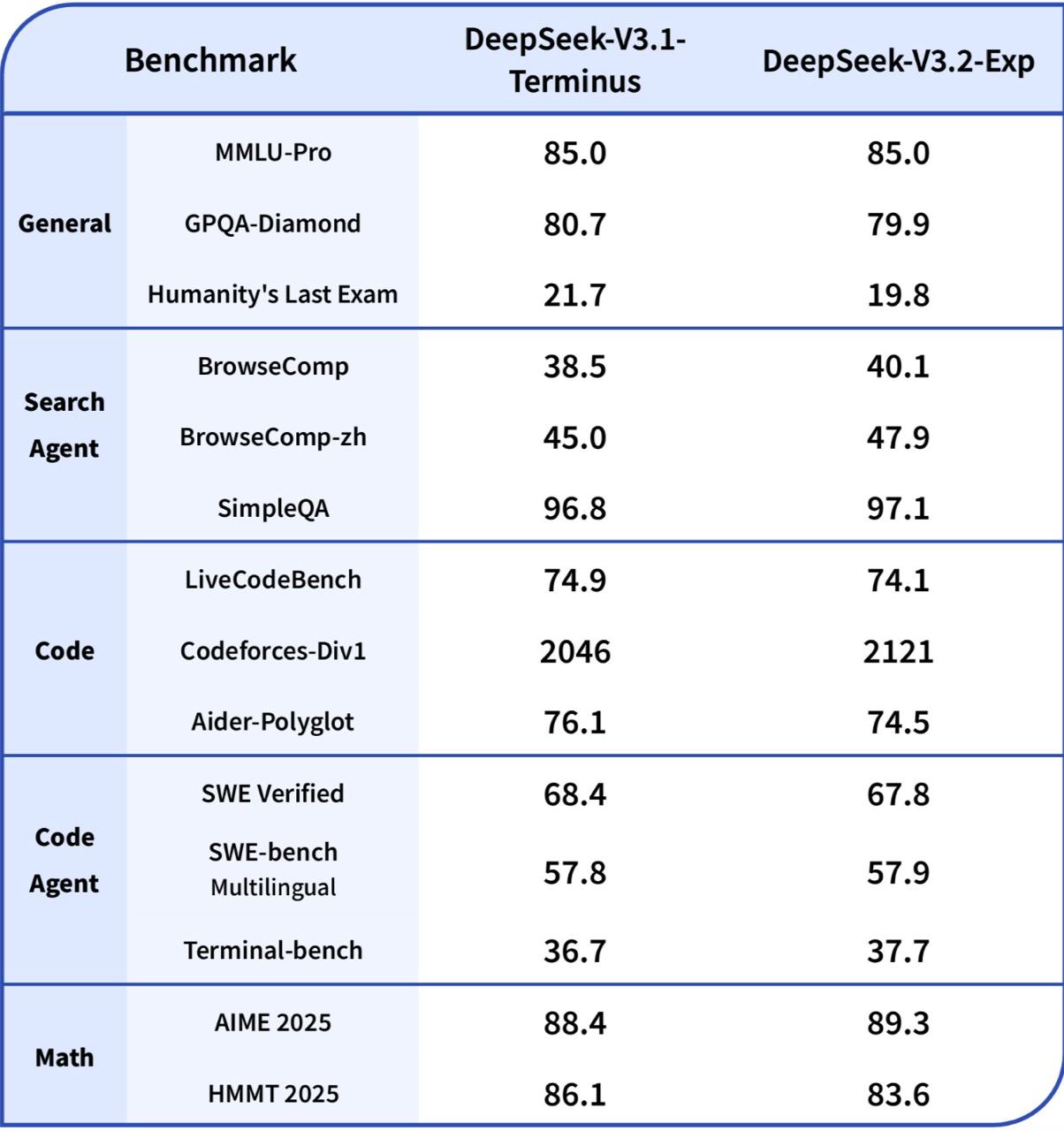
Представлена новая экспериментальная версия модели DeepSeek — DeepSeek-V3.2-Exp. Эта модель сохраняет качество на уровне предыдущей DeepSeek-V3.1 Terminus, но при этом предлагает значительно сниженные затраты на API и повышенную скорость работы с длинными контекстами.
Основное нововведение, позволившее достичь этих улучшений, — это DeepSeek Sparse Attention (DSA). Этот механизм является специальной вариацией внимания, которая позволяет модели вычислять аттеншен не на всех парах токенов, а избирательно, фокусируясь только на наиболее релевантных частях входного текста.
В большинстве реализаций Sparse Attention маска для всех запросов совпадает (то есть все токены смотрят на одни и те же позиции), но в DeepSeek-V3.2-Exp заявлен "fine-grained" подход. Это означает, что маска формируется динамически для каждого токена. Такой подход позволяет модели не терять важные зависимости в данных, обеспечивая сохранение качества при почти полном отсутствии падения производительности. Ускорение достигается за счет того, что сложность алгоритма становится линейной относительно длины последовательности, вместо квадратичной.
В результате применения DSA, стоимость API была снижена более чем на 50%, а местами — до 75%. Например, миллион токенов теперь стоит $0.42 вместо прежних $1.68.
Модель DeepSeek-V3.2-Exp уже доступна в веб-версии, приложении и через API. DeepSeek также подтвердила, что модель выпущена в open-source.
Важно отметить, что предыдущая версия DeepSeek-V3.1 Terminus будет доступна до 15 октября 2025 года.
Ссылки:
Основное нововведение, позволившее достичь этих улучшений, — это DeepSeek Sparse Attention (DSA). Этот механизм является специальной вариацией внимания, которая позволяет модели вычислять аттеншен не на всех парах токенов, а избирательно, фокусируясь только на наиболее релевантных частях входного текста.
Sparse Attention — это механизм в нейронных сетях, который позволяет модели обращать внимание только на наиболее релевантные части входного текста, значительно снижая вычислительные затраты по сравнению с традиционным механизмом полного внимания.
В большинстве реализаций Sparse Attention маска для всех запросов совпадает (то есть все токены смотрят на одни и те же позиции), но в DeepSeek-V3.2-Exp заявлен "fine-grained" подход. Это означает, что маска формируется динамически для каждого токена. Такой подход позволяет модели не терять важные зависимости в данных, обеспечивая сохранение качества при почти полном отсутствии падения производительности. Ускорение достигается за счет того, что сложность алгоритма становится линейной относительно длины последовательности, вместо квадратичной.
В результате применения DSA, стоимость API была снижена более чем на 50%, а местами — до 75%. Например, миллион токенов теперь стоит $0.42 вместо прежних $1.68.
Модель DeepSeek-V3.2-Exp уже доступна в веб-версии, приложении и через API. DeepSeek также подтвердила, что модель выпущена в open-source.
Важно отметить, что предыдущая версия DeepSeek-V3.1 Terminus будет доступна до 15 октября 2025 года.
Ссылки: